Benchmarking (raw) speech recognition APIs
A very short test to choose API at the time of the writing.
This is a research draft and while its aim is to benchmark APIs, it recommends tools that have not been benchmarked. So if you feel some tools would better fit, please reach out!
- api.ai: untested -> paid plan required
- Amazon voice service: untested -> german model unavailable (english only)
- Nuance ASR: tested
- Google Voice Service: test planned -> waiting for the use request approval
- Microsoft Cognitive Services (formerly Project Oxford) Speech To Text API: untested -> unless you use their SDK (iOS, Android, C#), you cannot stream to their service and only use a REST API with no partial result streaming.
From uses cases to audio files §
Would you want to replicate that little test, you need to use a few use cases to asses the variety of domains supported by the API. I focused on what my use cases were at the time: problem description with audio of varying length (15 to 256s, 6 use cases).
We used the following sequence for experiment purposes:
- Delivered an audio file with recorded search phrases to external services
- Received recognized text from automatic speech recognition service
- Evaluated quality metrics of recognized text vs. actual search phrase
Converting audio files §
Here I used the sox CLI tool, which stands for Sound eXchange. I actually just needed to convert a stereo 44.1kHz floating point mp3 file to 16kHz, merge it into a single mono file, convert the mono file to a signed PCM, process some filter on the raw files, convert them back to mono WAVs (that’s the api.ai requirements). To accomplish this, I used these commands, which were neither well documented, nor correctly referred to by most of the blogs I’ve read today, even five years later¹.
First, if you don’t know what your audio files are made of, use soxi:
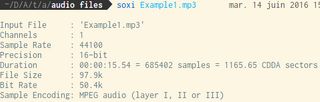
Then, the basics. The following converts to wave, only keeps the left channel (channel 1, thus converting to mono if it wasn’t already) and to a sample rate of 16000kHz with the sox intents.
sox Example1.mp3 Example1.wav channels 1 rate 16k
But the signed PCM² is still lacking.
sox Example1.mp3 -e signed-integer Example1.wav channels 1 rate 16k
Problem n°1: we have to take into account more information-rich files (especially stereo, even if it is unlikely with phone or laptop microphones). Here we keep stereo info by doing a mix-down of both channels, averaging them:
sox stereo.wav -c 1 mono.wav avg
Problem n°2: we have to reduce clipping. Clipping is distortion that occurs when an audio signal level (or ‘volume’) exceeds the range of the chosen representation. In most cases, clipping is undesirable and so should be corrected by adjusting the level prior to the point (in the processing chain) at which it occurs.
In SoX, clipping could occur, as you might expect, when using the vol or gain effects to increase the audio volume. Clipping could also occur with many other effects, when converting one format to another, and even when simply playing the audio.
For these reasons, it is usual to make sure that an audio file’s signal level has some ‘headroom’, i.e. it does not exceed a particular level below the maximum possible level for the given representation. Some standards bodies recommend as much as 9dB headroom, but in most cases, 3dB (≈ 70% linear) is enough. Note that this wisdom seems to have been lost in modern music production; in fact, many CDs, MP3s, etc. are now mastered at levels above 0dBFS i.e. the audio is clipped as delivered³.
All of that can be fine tuned by hand, and I tried a few tweaks that may prove useful on other, more complicated examples. But as my dataset was quite simple, and sox has a neat -G option to do it automagically, I used the latter.
Problem n°3: Dither. Same thing. Sox does a lot and dither awaits around the corner. Apply dither whenever reducing bit depth, to ameliorate the bad effects of quantization error, with the dither sox intent.
All of that to obtain a good input audio file: